
Quizás muchos de ustedes hayan oído hablar alguna que otra vez del archivo “boot.ini” y que modificándolo podemos tanto echar a perder nuestro sistema operativo o hacer algo verdaderamente útil, como cuando tenemos varios sistemas operativos instalados (que sean Windows claro) podemos modificarlo y lograr que uno arranque primero y otro después, y determinar cuánto tiempo tendremos para elegir el que queremos arrancar; pero lo interesante es que existe una herramienta en nuestros Sistemas Operativos para realizar estos cambios, es una que se ejecuta en nuestro MS-DOS, es claro que ya muchos sabrán de esto, pero bueno para los que no conozcan del tema se llama “bootcfg” y no es más que una herramienta para modificar nuestro archivo de entrada de inicio “boot.ini”. Ahora, a lo nuestro, como podemos utilizarla, pues muy sencillo (aunque a veces es bastante complicado). Ponemos en nuestro DOS de cada día lo siguiente: Lista de parámetros: Lista de parámetros:
bootcfg /parámetro [argumentos]
En donde “/parámetro” va a ser el parámetros deseado, en dependencia de lo que queramos hacer, a continuación les pongo una lista de los parámetros que podemos usar con este comando, la cual pueden obtener si ponen al comando “bootcfg” el parámetro “/?”.
/Delete: Borra una entrada de inicio existente en la sección [operating systems] del archivo BOOT.INI. Debe especificar el número de entrada que desea borrar.
/Query: Muestra las entradas de inicio actuales y sus configuraciones.
/Raw: Permite al usuario especificar cualquier opción de modificador para agregar a una entrada de inicio especifica.
/Timeout: Permite al usuario cambiar el valor Timeout.
/Default: Permite al usuario cambiar la entrada de inicio predeterminada.
/EMS: Permite al usuario cambiar el modificador /redirect para la compatibilidad desatendida para una entrada de inicio.
/Debug: Permite al usuario especificar el puerto y la velocidad en baudios para la depuración remota para una entrada de inicio especifica.
/Addsw: Permite al usuario agregar modificadores predefinidos para una entrada de inicio especifica.
/Rmsw: Permite al usuario quitar los modificadores predefinidos para una entrada de inicio específica.
/Dbg1394: Permite al usuario configurar el puerto de depuración 1394 una entrada de inicio específica.
Y donde los argumentos son los lugares o las características específicas de cada parámetro. Podemos obtener los argumentos poniendo el parámetro “/?” después de el primer parámetro.
Por ejemplo:
Bootcfg /Copy /?
Esto nos mostraría algo así como lo siguiente:
BOOTCFG /Copy [/S sistema [/U usuario [/P contraseña]]]
[/D descripción] /ID Id. inicio
Descripción:
Hace una copia de una entrad de inicio existente.
/U [dominio\]usuario Especifica el contexto de usuario en el que el comando debe ejecutarse.
/P contraseña Especifica la contraseña para el contexto de usuario dado.
/D descripción La descripción de la entrada hecha del sistema operativo.
/ID id_inicio Especifica el Id. de entrada de inicio en la sección [operating systems] de BOOT.INI en el archivo para el que se tiene que hacer la copia.
/? Muestra esta ayuda/uso.
Ejemplos:
BOOTCFG /Copy /D "Windows XP con depurador" /ID 1
BOOTCFG /Copy /S sistema /U usuario /D "Windows XP" /ID 3
BOOTCFG /Copy /D "Depuración de errores de Windows XP" /ID 2
Así de esta manera podemos obtener una ayuda detallada de todos los demás parámetros para obtener de esa forma así sus respectivos argumentos.
Pero lo más interesante no es esto, sino que este archivo existe al menos desde nuestros viejos sistemas operativos (Windows) hasta el XP, ya que en Vista todo tuvo un giro totalmente radical, ahora el archivo no se llama “boot.ini” sino “BCD”, y ¿dónde se encuentra?, todavía no lo descubro, pero existe una herramienta como en nuestro XP que se llama “BCDedit” que sirve para hacer lo mismo que la anterior y muchas más cosas que estas y a su vez ofreciendo una mayor seguridad. ¿Cómo la utilizo?, ah, pues muy fácil, igualmente ponemos en la consola del Vista el comando de la siguiente forma:
bcdedit /parámetros [argumentos]
Igual no, bueno solo que los parámetros y los argumentos no son los mismos, pero bueno esto se los dejo a ustedes, ya que los pueden averiguar si escriben en la consola:
Para obtener los parámetros y para lo que sirve:
bcdedit /?
Y para obtener los argumentos u otros parámetros:
bcdedit /parámetro /?
Bueno amigos esto es todo por hoy, espero que les haya resultado interesante y hasta la próxima.
lunes, 25 de agosto de 2008
Arranque de Windows
Tutorial de transportes
Como a mi me pasó ahora a muchos de nosotros nos ha sucedido que teníamos Internet (estábamos en cuna de oro, XD) y sin más ni menos se desaparece ese sueño y llegan los “Hay mi madre!!”, perdemos el correo, los contactos… y creemos que todo esta perdido.
Pues en este tutorial no les puedo enseñar como recuperar su preciado correo en Yahoo ni en Hotmail o Gmail, pero al menos les puedo indicar como recuperar los contactos que tenían en el Windows Messenger y el Yahoo Messenger. Todo radica en una potente herramienta que nos ha regalado el equipo de Softwarelibre.cu es simple y llanamente el jabber.
Cada ves que tomamos el Psi y le damos en la opción “Descubrir Servicios” nos aparece una serie de iconos de los distintos servicios que brinda el servidor al que nos conectamos entre ellos están los Transportes que nos ayudan a conectarnos mediante el servicio de jabber a nuestras respectivas cuentas en algún que otro servicio de mensajería instantánea. Lamentablemente nuestro servidor de jabber no tiene este tipo de transporte pero hay otros que si como es el caso de este que vamos a utilizar el ihrisko.org.
1. Para comenzar vamos a la opción Descubrir Servicios del Psi.
2. Luego quitamos la dirección de nuestro servidor (softwarelibre.cu) y ponemos la de ihrisko.org como nos muestra la imagen a continuación en el área marcada en rojo.
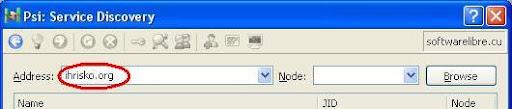
Luego esperamos a que carguen los servicios. Cuando estén cargados todos los servicios vamos al de Yahoo o al de MSN y le hacemos clic derecho, cuando nos salga el menú desplegable damos clic en registrar, luego escribimos nuestro usuario de yahoo y nuestra contraseña en el cuadro de dialogo que aparece en la imagen a continuación.
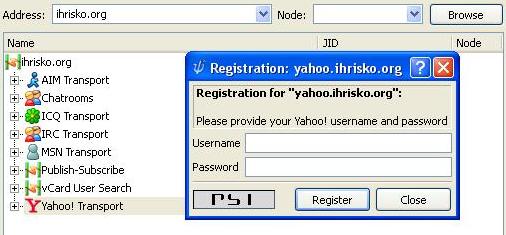
Luego damos clic en registrar y listo. Solo tenemos que esperar a que el transporte se agregue a nuestra lista de contactos (para esto tenemos que autorizar al contacto del transporte) y ya tendremos nuestros contactos de Yahoo online nuevamente.
Para agregar nuevos contactos lo agregamos como cualquier contacto de jabber pero esta ves pondremos nombre de usuario @yahoo.ihrisko.org o @msn.ihrisko.org.
Ahora para usar el transporte de MSN repetimos los mismos pasos que con el de yahoo pero esta ves no pondrás solo tu nombre de usuario si no la dirección completa más tu contraseña, eje: tunombre@hotmail.com
Bien ahora puedes chatear nuevamente con tus contactos de Yahoo y MSN.
Nota: El transporte de Yahoo no acepta contactos de MSN ni el de MSN acepta contactos de Yahoo.
Espero que le halla gustado y ya saben nos vemos por ahí en la red cubana… sin mas un saludo de Alchemist.
No, no estamos solos
Este es un documento que muestro el trabajo que se quiere realizar con el proyecto Xtreme-Zone en nuestro país. Aquí se explica la idea como tal de proyecto además de mostrar varios aspectos que son de gran ayuda para nuestros usuarios.
Xtreme-Zone va dedicado especialmente a las personas que tengan afinación con el diseño web, la programación y administración de sitios web. En este boletín se muestran códigos, artículos, noticias, se trabaja la publicidad hacia sitios afines con el proyecto y otros que son importantes para el desarrollo de nuestra red nacional. Se trata de que los internautas aprendan de la red, tengan una cultura esencial y conozcan las posibilidades que esta nos brinda para el desarrollo tanto informático como intelectual de nuestra persona.
También se trata de enfatizar que con solo pocos recursos podemos lograr hacer grandes cosas. No solo pensar en Internet si no poder pensar en los recursos que tenemos y podemos explotar. Que no solo seamos dos o tres los que nos interesemos por la red y por su potencial, si no que todos los internautas vean las posibilidades que nos brinda la red y poder explotarla al máximo.
Se enfatiza en que se creen sitios especializados para diversos servicios que pueden ser creados en la red. No solo crear sitios de ajedrez, medicina, los Joven Club y otros, si no crear sitios de diferentes cualidades culturales.
En nuestro país existen sitios especializados en los webmasters, pero Xtreme-Zone trata de llegar más a fondo con el tema, tratando de llevar a los usuarios cada día un poco más de este conocimiento. No solo tenemos que ser unos pocos los que sabemos si no que muchos pueden saber y aprender para no tener que depender de otras personas.
El diseño web es una tendencia que aquí en nuestro país no se ve como un arte o como un gusto, si no como un trabajo, y no todos pensamos igual. Yo como persona trato de que cuando hago un sitio o un proyecto me sienta bien y no piense en las ganancias que este me pueda traer.
Vivimos en un país bloqueado, pero con pocos recursos podemos llegar a ser grandes, y no lo hacemos. No hablo de los Chats, ni foros si eso es lo que piensan las personas que lean este documento. Hablo de crear nuevas ideas, de poder organizar la red y poder crear sitios webs especializados para cada tema. Ejemplo de esto, es el porqué no crear un sitio web de SCI-FI que es una tendencia bastante utilizada en nuestro país y ha dado bastantes frutos. Porque no crear una web solo para los webmasters de nuestro país, donde todos podamos debatir, aprender, poner utilidades que puedan ayudarnos y compartir criterios para así poder tener un gran ejercito de personas con un alto conocimiento y no tener que depender de la Internet para poder ser mejores.
Actualmente estamos trabajando en otro proyecto muy ambicioso pero que se piensa que algún día de sus frutos hacia la red y hacia nuestro país. El proyecto es llamado AWC “Asociación de Webmasters Cubanos” en el que todos los webmasters podamos hacer conferencias a nivel nacional, congresos, crear sitios webs para nuestro país y ayudar al fortalecimiento de la red nacional para lograr ser una pequeña potencia en la Internet y poder sobresalir aún más.
Cada proyecto en la red comienza con algo. Tanto Xtreme-Zone con AWC están comenzando bastante bien aunque siempre se nos dificultan algunas cosas que no están en nuestras manos. Anteriormente en este mismo artículo hablaba de AWC. Este proyecto pretende ser el que ayude a otros proyectos a poder ser conocidos. A trabajar en reagrupar todas las fuerzas en la red nacional. Trato de llevar cada mes una nueva edición con variadas noticias y artículos, además de otras utilidades a los internautas que se han suscrito al boletín Xtreme-Zone.
Queremos lograr una comunidad entre los proyectos que circundan nuestra red, pero para ello necesitamos de personas que de verdad tengan el poder necesario para asi lograr nuestro objetivo. Solo somos un grupo de chicos que quieren el bien para la comunidad de webmasters e internautas de la red.
Contamos con afiliados de diferentes temas, no solo sobre el diseño web y otros sino también sobre el hack, las utilidades de nuestra PC, el Anime, Manga, SCI-FI y muchos otros temas.
“Lograr una comunidad es el principal objetivo que tenemos que profundizar para poder ser una potencia en la informatización digital”
Muchas son las personas interesadas en dichos proyectos. Entre los que encontramos a Juan Pablo, webmaster y creador del proyecto Infonoti el cual trata de dar noticias y artículos varios de diferentes temas entre los que se encuentran, videojuegos y consolas, electrónica, redes, telefonías móviles entre otras. Dicho webmaster también es el creador de un proyecto similar a Xtreme-Zone llamado Zona Web en la que se brindaban utilitarios que facilitaban el trabajo de los webmasters en nuestro país. Así como este existen otros pero no todos se unen. La mayoría son proyectos estatales que brindan sus servicios a diferentes entidades. Nosotros lo hacemos para sentirnos bien, ayudar a las personas que no cuentan con el servicio de Internet y a personas que recién comienzan en este mundo de la intranet y no saben cómo van a empezar.
Uno de mis grandes amigos y que hago mención aquí es Chacal (Ariel) el cual estuvo en contacto conmigo cuando comencé con el proyecto y que me ayudó con la idea original que poco a poco he ido modificando. A él lo considero como Co-Fundador del proyecto por ayudarme cuando más necesitaba la ayuda de las personas.
Hemos implementado a Xtreme-Zone el servicio de publicidad para así dar publicidad a los nuevos proyectos de la red al igual que lograr la comunidad que tanto deseamos con los afiliados.
Ahora con AWC queremos que los proyectos de la red tanto boletines, como websites se afilien al proyecto para poder brindar entre todos los servicios que muchos de nosotros no tenemos acceso.
Exhorto a todos los que deseen unirse a este ejército de personas por el bienestar de la red que lo haga mediante el proyecto Xtreme-Zone.
Atentamente su servidor _Romeo_Administrador de EIEFD. Creador y fundador del proyecto Xtreme-Zone. Fundador y creador del proyecto AWC. Diseñador del proyecto Otaku D’ Cuba.
Dulces sueños
“… Belerofonte mató la bestia que arrojaba fuego por la boca, y así el reino de Licia pudo dormir en paz” Mitos Griegos
La historia comienza un día cualquiera, en cualquier pequeño pueblo a donde el destino fijó mi morada, el administrador – de sistemas claro está – se levantó temprano como era costumbre y se marchó a trabajar. Como es usual era un buen admin, por consiguiente no tenía mucho que hacer, ya que como saben en nuestro empleo – sino tienes servidores de correos, web, ftp, etc. – los papeles se hacen el primer día y sirven casi para toda la vida, solo tienes que cambiarles la fecha. Sino fuera por la clásica rutina de una auditoria – a la que esperaba tranquilo – todo habría sido solo un aburrido día más.
Lo que él no sabía era de la existente disconformidad de los auditores – resentidos por problemas personales –, que buscaban un chivo expiatorio en quien descargar algunas iras no importantes ahora, ni el momento en que esto sucedió. Pero eso ya es otra historia – más bien chismes de barrios – lo que sucedía aquel día era – quizás para sorpresa de sus extremistas visitantes – que todo marchaba demasiado bien.
Luego de horas de trabajo forzado por encontrar la mínima muestra de delitos Dios favoreció la perseverancia y en la máquina numero 6 de las auditadas por fin apareció algo – lo único creo – la imagen semidesnuda – ligera de ropas diría alguien, aunque yo preferiría semivestida pues soy bastante optimista – de alguna modelo.
Después de esto hubo silencio, nada más ocurrió en el mundo público, pero nada se había detenido, la maquinaria giraba en los engranajes de las reuniones a puertas cerradas y chismes de pasillos. Y así pasaron los días.
Otro día cualquiera – algún tiempo después claro está – otro administrador se despertaba con la tranquilidad de saber su “trabajo bien hecho” y este hubiera sido un día más – aburrido – sino se hubiera enterado de los chismes del mundo.
Habían encontrado – entre archivos eliminados – una foto – tremendo delito recogido en los reglamentos de toda entidad y resoluciones ministeriales, cosas esas que usualmente nadie lee – y le habían aplicado una medida al admin fulano de tal y a los técnicos que con el trabajan, impactante noticia en Infierno Grande. Lo más impactante – y extremo – era que la foto era de al menos 5 años atrás, cuando para colmo el admin aun no trabajaba en ese lugar.
De pronto quedé estupefacto – altamente preocupado además – yo también era un inocente admin durmiendo dulces sueños con mi cabeza en el cielo, y mi cuerpo en el infierno. Que para colmo había comenzado a trabajar en algún dichoso lugar después de que las máquinas habían sido instaladas con anterioridad.
¿Cuántos usuarios pasan a diario por mis máquinas? – o por las de cualquiera.
¿Cuántos regalos como ese tendría yo guardados entre los archivos borrados, en las profundidades del subsuelo de mis workstations?
No lo sabía. Y eso era ya suficiente para alejarme de inmediato de mis dulces sueños. El fantasma de las perturbaciones había colocado una gran preocupación en mi subconciencia y había envenenado mi existencia feliz. Pues cualquiera – yo mismo, tú o ella – podíamos ser victimas de la injusticia justiciera de cualquier idiota oportunista, resentido contra alguien.
Luego de meditar por algún tiempo decidí que era tiempo suficiente de dedicarme a buscar la solución a esta pequeña dificultad peligrosa. Por eso me dispuse a estudiar al enemigo, pues decidí que debía matar al dragón que vivía en mis dominios antes que viniera alguien le despertara y este me matara a mí.
Conociendo al “enemigo” Master File Table
En la investigación realizada se encontró que la llamada tabla maestra de ficheros (MFT) es el corazón de la estructura de ficheros de Microsoft Windows NT – NT, 2000, XP, SERVER, etc.). Esta no es más que un archivo (fichero) – un archivo invisible – especial del sistema, cuya esencia no es más que una base de datos que contiene información sobre todos los ficheros y subdirectorios (carpetas para la gente de la Windows era) existentes en el interior de una partición – volumen lógico – NTFS. Como cualquier base de datos “nuestra” MFT es una colección de registros para cada archivo y subdirectorio en el volumen lógico. Cada registro tiene una longitud de 1024 bytes y contiene como información los atributos de estos archivos, información que le dice al sistema como tratar con cada archivo.Lo más interesante – a juicio del autor – acerca de MFT es que algunas veces almacena la actual data del fichero con toda la data relativa al fichero – tremendo chismoso ;) – la data almacenada dentro de la MFT es conocida como resident data (data residente). Esta puede tener importancia significativa concerniente a asuntos de seguridad informática con respecto a potenciales fugas – pérdidas – de datos sensibles por accidentes.
Es seductor exponer aquí que no existen cabos sueltos asociados con un fichero almacenado dentro de la MFT. La razón es que – por definición – esta es un área que marca desde los inicios hasta el final del fichero y el final del último cluster asociado a este fichero. En este caso, todos estos datos no residen en un cluster específico, residen en el archivo conocido como MFT.
Leyendo se encontró en otra parte que NTFS reserva los primeros 16 registros de la tabla para guardar cierta – ;) – información especial, y realizando un análisis de estos registros vemos que más o menos simplificadamente es así como están definidos:
El primer registro es el descriptor de la tabla en si o sea el índice, el cual es seguido por la MFT espejo (MFT$), la cual justifica su existencia porque si el primer registro se corrompe, NTFS lee el segundo registro para cargar los datos almacenados en él, al cual si comparamos con el primer registro descubrimos que es idéntico, con lo cual – sorpresa – puede autorepararse la tabla de asignación de ficheros. Otro asunto de interés es que la posición de los segmentos de datos – data segments – para ambas – MFT y MFT $ – están grabadas el sector de arranque (boot sector). A la vez que un duplicado del sector de arranque es almacenado en el centro del disco lógico.
El tercer registro de la MFT es el llamado “log file”, este es usado para – sorpresa – la RECUPERACIÓN DE FICHEROS, empleando para ello las posiciones del registro 17 en delante de la base de datos, los cuales representan cada fichero y (sub) directorio (interpretado como fichero claro está) existente en el volumen.
Nota: Los subsiguientes registros hasta el 16 no son del interés de este artículo por eso no son tratados.
Otro asunto de relativa importancia es la forma en que son interpretados los directorios: estos son tratados dentro de la MFT como simples ficheros, pues de manera similar a los datos los directorios contienen información, la diferencia radica en que esta se recoge ordenadamente y se utiliza como índice a su vez. Los directorios pequeños – sin directorios interiores – se recogen de manera entera dentro de la estructura MFT. Mientras que los largos son tratados como árboles binarios, con punteros – apuntadores – a clusters externos que contienen, a su vez, entradas de directorios que no pueden ser contenidas dentro de la estructura de la MFT.
Como quiera, pareciera que aun pueden existir “cabos sueltos”, pero son otro tipo de cabos sueltos, son los cabos sueltos que son el problema de nuestra investigación – cabos sueltos que al parecer no fueron tan sueltos – conocer de su existencia es lo los que hace fuerte a los investigadores y a los especialistas en seguridad, ya que la informática forense – csi en ciberworld – utilizan herramientas que capturan los ficheros borrados de manera supuestamente segura. Buscando su existencia entre los denominados por el autor “cabos sueltos”, pero no dentro de la MFT sino de la MFT$, tratando a esta como si fuera simplemente la MFT.
Esto se debe a que cuando se borra un archivo, simplemente se borra de la MFT, y se elimina de esta borrando el primer carácter del nombre, que es sobrescrito con un carácter especial que indica que ese registro está vacío y a la espera de que nueva data necesite ser almacenada en el disco, mientras que en el disco permanecen los datos supuestamente borrados, en cada uno de los clústeres, como esto ocurre a veces por accidente – y otros males - el espacio utilizado por este, y su ubicación en el volumen lógico aun se encuentra referenciado en la MFT$ y accesible a ciertas herramientas especiales – como un Restoration – o comunes como pueden ser en todo caso los undeletes.
Al concluir esta búsqueda quedaron todas las cosas claras, dejando absolutamente comprendido que cualquier método de borrado no es quizás lo suficientemente seguro. Pero que se le iba a hacer, seguimos trabajando con usuarios, que a su vez puede ser que nos dejen sorpresas de las que nosotros debemos haceros cargo, y – como se dice en voz común – debíamos enterrar sus muertos, que al estar en nuestras máquinas, se vuelven irremediablemente nuestros muertos.
Por ello y como se que este problema puede ser común para muchos de los que consultamos este documento, es que me siento a redactar algunas consideraciones a tener en cuenta para efectuar un borrado casi seguro, que pongo de esta manera en las manos del underground cubano, para que muchos de nosotros podamos seguir durmiendo en paz.
Pero antes se propone esclarecer que el autor considera un borrado seguro a aquel en que usando algún software – créanme he probado con muchos y solo uno me ha dado cierto resultado limitado –, método o la mezcla de ambos se logre eliminar un fichero sin la concebida posible recuperación, ya sea total, parcial, o simplemente conocer su anterior existencia en el ordenador.
Ideas elementales para un borrado seguro
La primera forma elemental de borrado casi seguro aplicable son las dos variantes del clásico se me borró la tesis, el cual tal vez no sea muy efectivo, pero es una solución elemental a nuestros problemas para una situación de crisis.Primera variante:
Muy sencilla editamos el archivo con cualquier programa editor – no importa que archivo, puedes incluso utilizar el Word – borra unas cuantas líneas de lo que te abra en pantalla, salva el documento y seguidamente elimínalo.
Ventajas:
Cuando usas el recuperador de archivos recuperas un archivo ilegible
Inconvenientes:
El archivo ilegible aun te deja enseñando los bloomers pues conserva nombre y extensión, y aunque nadie pueda abrirlo, todo auditor sabe lo que es un jpeg, un mpeg, un avi, etc.
Segunda variante:
Crea con el bloc de notas un archivo vacío – 0 (cero) bytes – llamado – por ejemplo – noname.txt, guárdalo en una locación distinta a la que posee el archivo que vas a eliminar, renombra el archivo que quieres eliminar con ese mismo nombre y cópiale encima el archivo que creaste con el bloc de notas, lograrás engañar de esta manera al MFT, y obtendrás un borrado seguro en un 75 %.
Ventajas:
Obtienes un borrado bastante seguro pues te ahorras las extensiones delatoras.
Inconvenientes:
Esto es factible cuando borras un par de ficheros, pero que tal si tienes que borrar, las 6 temporadas de 24, cada una con su correspondiente subtítulo aparte, o 20 gigas de música. Tarea demasiado engorrosa digan de titanes. Ni alargando los días a 48 horas terminas con la segunda en una semana.
Una idea aparentemente más profunda
La idea subsiguiente parece una mejor solución, simplemente formateas la máquina – pero es solo en apariencias una buena idea – incluso podemos pensar en una reinstalación.Ventajas
Supuestamente has destruido toda la data que te incriminaba, pero echemos un ojo primeramente a las desventajas.
Desventajas
Solo es valida si:
• Tienes una sola máquina.
• El formateo realizado es a bajo nivel.
• No tienes grandes volúmenes de información que puedas perder.
¿Por qué una máquina? No me digas que se te echaron a perder tus n (donde n >> 1) máquinas a la vez y ante la presencia de una auditoria inminente. Un poco extraño e incriminador este comportamiento, no te parece ;).
¿Por qué a bajo nivel? Porque incluso a bajo nivel existen warez especializados en la recuperación de formateos “accidentales”. O acaso no han escuchado de la historia de “se me formateó la máquina solita”.
¿Por qué grandes volúmenes de información no es recomendable? Porque esta cantidad de información vital debe estar disponible y no debe perderse, porque si es muy sensible puede que incluso puedas ir preso.
Pero la existencia de grandes volúmenes es un caso especial que si es discutible a raíz de un posible corolario que nos plantea que:
Una propuesta alternativa es la creación de tres particiones C, D y E. Donde C es la partición del sistema y los archivos de programa que instala Windows de manera automática – ojo xp real, no Windows desatentranca para usuarios inexpertos que se creen expertos -, D es la partición de tus archivos de programa – Office y toda la otra basura con la que trabajas – y E es la partición de los documentos de todos los usuarios que trabajan en la misma, pues sería cosa fácil mover los documentos – una vez borrada toda la basura – formatear esta última partición, y devolverlos luego a su lugar de origen.
Esto te brinda al menos un 85 % de seguridad, sobre todo si sabes lo que es un formateo de bajo nivel, y como llevarlo a cabo.
Belerofonte o las ideas originales a discutir en este material.
La próxima solución es la solución recomendada por el autor, para ello vas a utilizar un par de software el Norton Ghost 2003, y el Restoration 3.2.13, y la imagen de Ghost que se anexa a este material, con ellos lograremos un borrado en un 98 porciento de seguridad.Para ello previamente tendrás compartida tu máquina como explicamos con anterioridad – acostúmbrate a trabajar organizado – con tres particiones, le habrás asignado un espacio de 7 Gb a la unidad C (sistema) y las unidades D y E tendrán el mismo tamaño.
El truco consiste – simplemente – en copiar los datos de E para D una vez eliminado los archivos que te hubieran hundido más profundo que al Titanic, seguidamente realizarás una restauración de la imagen "limpiadora_de_disco" que se crea utilizando el propio Ghost erigiendo una copia de respaldo de un disco duro vacío con un formateo a bajo nivel, que es envejecido con cada día que transcurre, lo cual la hace muy creíble hablando en términos forenses – y que fue creada con Ghost – en la partición D.
Esto se realiza – el autor pide disculpas ya que esto no es un tutorial paso a paso para principiantes, simplemente tratará de exponerlo de la manera más sencilla, pues prefiere dejar en manos de los especialistas en tutoriales explicar cómo realizar una restauración – sin muchas complicaciones para lo cual vamos a la opción restaurar del Norton Ghost y seguimos los pasos correspondientes para realizar una restauración del volumen.
Concluida esta primera parte ya podemos regresar toda la data movida a su lugar de origen, ya hemos limpiado de todo rastro acusador la MFT (en realidad hemos sustituido una MFT por otra, pero el resultado obtenido es igual a una MFT limpia ;). Nada, un poquitico de ingeniería social aplicada) y estamos en un 90 porciento libre de toda traza. Con lo que una vez finalizada esta operación podemos dar por concluida nuestra tarea, no obstante si ustedes son medios paranoicos como el autor – hecho este que considero una ventaja teniendo en cuenta cualquier eventualidad – aún podrías no sentirte seguro con la limpieza realizada, para ello te propongo “laves” también los clusters.
Para la limpieza de los clústeres se ejecutará el Restoration, en el cual se elegirá la opción Delete Completely del menú Others que realizará entonces la limpieza de los clusters copiando clústeres en blanco sobre cada uno de ello. Con esto si habrán concluido tus temores “normales” – resueltos en un 98 %, pues te advierto que existen más formas de saber que has hecho en tu máquina, por suerte todos los auditores no tienen tan alto coeficiente intelectual – y sentirte un poco más seguro, ya puedes regresar a la normalidad de una vida tranquila.
Cabría ahora realizarse algunas preguntas inteligentes para dar por concluida esta exposición.
¿Por qué no efectuar solamente una limpieza con el Restoration? Porque el Restoration solo limpia los clústeres, no limpia la MFT, si el programa de recuperación utilizado por los auditores hace un escaneo profundo en la MFT – son más usuales este tipo de recuperadores – encontrarás el nombre del archivo y su extensión, y una explicación de que es imposible su recuperación pues el archivo está corrupto. Por otro lado se debe agregar que el proceso de limpieza con el Restoration es bastante lento.
¿Entonces es más recomendable – si debiéramos elegir – realizar la limpieza con el Ghost? En cierta manera si, pues como ya se explicó anteriormente la mayoría de los recuperadores basan sus algoritmos en búsquedas y comparaciones en la MFT, pero qué tal que se hiciera con alguna herramienta para recuperar los contenidos de los clústeres. Creo que esta es una solución para una limpieza ágil y rápida. Pero se recomienda la utilización mezcladas de ambas técnicas, o sea un borrado a lo Belerofonte.
¿Cuándo copiamos los archivos a D, para hacerle la salva, y luego los borramos de D, al ser estos restaurados, no estaremos creando nuevas trazas de elementos eliminados en el disco duro?
Si, esto es totalmente cierto, pero se debe limpiar primero la casa antes de hacer la salva, o sea antes de copiar en D primero debemos eliminar los archivos ilegales que se encuentran en E – por supuesto con el método clásico del Shift + Del – hacer entonces la copia, limpiar con alguno de los procedimientos propuestos, y devolver los archivos a su lugar de origen. Si has trabajado con pulcritud no tienes que preocuparte por los archivos que quedan eliminados en la torre D, porque son archivos utilizados en tu lugar de trabajo y es normal que se encuentren estos tipos de archivos eliminados en el disco duro.
Ahora si – creo yo – que ya estamos listos para tener dulces sueños.
El autor, que gusta de vivir en el anonimato, es graduado del superior en una ciencia exacta y una carrera técnica, tiene 33 años aproximadamente, tuvo su primera experiencia con ordenadores a los 8, no se considera genio ni ha_cker pero si alguien que ha pasado mucho tiempo en el medio y más sabe el diablo por viejo que … ha trabajado como admin en diferentes lugares desde los 17 años, su verdadero alias es bastante conocido en su región por lo que para vivir en reposo prefiere ser llamado MisterIO (Mr I/O).
Tiempo de ejecución (Parte 2)
Definición 3:
T(n) es q( f(n) ) si es O(f(n)) y W(f(n)).
En el ejemplo anterior, el caso peor es q(n)
Puntualmente, se puede hablar de O, q y W para el caso peor, para el caso promedio y para el mejor caso. No siempre hay coincidencia en sus valores.
Cuando decimos que un algoritmo es O(f(n)) significa que a partir de un determinado tamaño de la entrada, el tiempo de ejecución va a ser menor o igual que f(n) multiplicado por una constante.
Para darle una cota superior al tiempo de ejecución del algoritmo, o sea, calcularle una O, se trabaja con el caso peor.
Cuando decimos que un algoritmo es W(f(n)) significa que a partir de un determinado tamaño de la entrada, el tiempo de ejecución va a ser mayor o igual que f(n) multiplicado por una constante.
NOTAS:
- Cuando el tamaño de la entrada está acotado, o sea que no tiene sentido considerar valores de n todo lo grandes que se quiera, NO tiene sentido hablar de O, W, ni q
- En la práctica lo que hacemos es calcular O grande y a partir de ahí, afirmamos que el tiempo de ejecución del programa será de un orden proporcional a dicho valor.
- El término de cota superior no es exactamente interpretable como se hace en análisis matemático, es mejor considerar el término asíntota (cada vez más T(n) se va acercando a f(n), que es la asíntota en este caso, pero nunca se funden ambas funciones).
- Analizar el caso de la función T(n)= an² + bn + d que es O(n²), es decir se cumple la siguiente desigualdad an² + bn + d <= cn² para n>=n0 . Destacar que a partir de un n suficientemente grande, los dos últimos términos de T(n) se vuelven despreciables pues el término en se dispara vertiginosamente, o sea, su velocidad de crecimiento. En el análisis gráfico, va siempre por encima la curva de cn² y por debajo la de T(n). Al principio existe una cierta distancia inicial que las separa, pero a medida que n va siendo suficientemente grande, esa distancia se reduce considerablemente, de forma tal que parece que ambas funciones se van a pegar. Esa distancia la establecen, precisamente los dos últimos términos de T(n), o sea, los que son despreciables cuando n es suficientemente grande.
- Una T(n) que es O(n²) también será O(n²), O(n³), .... , precisamente me quedo con la primera porque es la que más se ajusta. Debe verse que O(n²) constituye una familia de funciones, que contiene a todas aquellas funciones que son precisamente O(n²), y así sucede para todas las otras. Un miembro de la familia de O(n²), también lo será de todas las demás familias, pero a la inversa NO siempre se cumple, escojo entonces como O grande para T(n), aquella familia que menos miembros tenga, en este caso O(n²) y podemos decir que T(n) es miembro de la familia (pertenece) O(n²), aunque cuando hablamos en términos de algoritmos lo mejor es decir, “T(n) es O(n²)”
- Se debe, en cada caso, dar la cota superior e inferior que más se ajuste (exprese con mayor exactitud, o sea de las superiores, la menor posible y de las inferiores la mayor posible) al algoritmo. El caso ideal sería cuando coincidieran ambos, que es cuando entra a jugar el concepto de q.
Cálculo del Tiempo de ejecución.
El cálculo del tiempo de ejecución de un programa, sería bien engorroso, pues sería una suma de constantes c1, c2, ...., cn ( una por cada instrucción) y a su vez, el cálculo de cada una de ellas sería impracticable, pues dependería, en cada caso, de las características de la máquina donde se ejecute el programa. Por tal motivo, lo que se hace en la práctica es calcular O grande, y a partir de ahí, podemos decir, el tiempo de ejecución del programa está acotado, superiormente, por dicho valor.
Algunas reglas para calcular los ordenes O, en elementos individuales dentro del cuerpo del programa, serían las siguientes:
Regla de la SUMA:
Si tengo varios ordenes sumados, me quedo con el mayor
Regla de la PRODUCTO:
Si tengo varios ordenes multiplicados, me quedo con el producto
- Todas las operaciones atómicas son O(1). Ej: asignaciones, suma, resta, etc
- Una secuencia constante (que no dependa de n) de instrucciones es O del máximo de las O particulares correspondientes a cada instrucción de la secuencia. En este mismo sentido, si existen dos segmentos de programa p1, p2 y p2 se ejecuta inmediatamente después de ser ejecutado p1, el orden de la secuencia total, es el máximo entre el orden de p1 y el de p2, de aquí, se deduce la regla de la suma: el orden de una suma de ordenes, es el mayor orden que aparece entre los sumandos
- regla del producto: el orden de un producto de ordenes, es dicho producto.
- En un ciclo su tiempo de ejecución está acotado superiormente por la cantidad de veces que el cuerpo del mismo se ejecuta, multiplicado por el orden de la secuencia de instrucciones que se ejecuta dentro de él. Se aplica la regla del producto.
- En una sentencia del tipo if-then-else, el O de la misma se calcula mediante la suma del tiempo requerido para evaluar la condición, por lo general O(1), mas el mayor entre los O correspondientes a la secuencia de instrucciones del if y del then.
En estas reglas no se ha tenido en cuenta el caso de procesos recursivos. Por lo general la expresión de la función de tiempo para estos casos es de la forma:
.png)
a, b, y n0 son enteros positivos
La idea es que mi problema de tamaño n es descompuesto en a subproblemas de tamaño n/b, para obtener la solución del problema de tamaño n, a partir de dichos subproblemas. Consideramos que integrar las soluciones particulares de cada uno de ellos, para obtener la solución general del problema, consume un tiempo h(n)
Idea:
T(n) se subdivise en T1(n/b) ………. Ta(n/b)
Cada Ti genera una Sol i particular para el subproblema i
h(n) es el tiempo necesario para integrar las a soluciones, Sol 1 …. Sol a, a partir de las cuales se obtiene la solución general del problema.
Ej: Buscar el máximo en un arreglo sería:
.png)
Si el arreglo es de tamaño 1, retorno su único elemento en O(1).
De lo contrario retorno, (en O(1)) el mayor entre el máximo de su primera mitad y el de su segunda mitad.
En este ejemplo a=b= 2 y h(n) es O(1)
Algunas reflexiones interesantes ..........
Si tenemos un programa cuyo tiempo de ejecución es O(log n) (Como por ejemplo lo es el algoritmo de “búsqueda binaria o dicotómica”), podemos considerar que tenemos una versión muy eficiente, en cuanto a tiempo de ejecución, de dicho programa.Por ejemplo
.png)
Sabemos que es un número suficientemente grande e interpretémoslo en este caso, como el tamaño de la entrada
Si nuestro programa consume un tiempo de ejecución de orden logarítmico, para el ejemplo en cuestión.png)
Recordar:
.png)
sea, que procesa todo el volumen de datos de la entrada, en 20 operaciones. Lo cual da idea de lo eficiente que es dicho programa.
Ej. Un número muy grande, podría ser:
.png)
Nota: En esta conferencia los estudiantes pueden manifestar dudas entre el concepto de O grande y el de o pequeña dado en análisis matemático y que también tiene una expresión para el análisis del tiempo de ejecución de un algoritmo.
Artículos relacionados:
Tiempo de ejecución (Parte 1)Como crear un CD o DVD de Windows XP Personalizado (Parte 1)
Rutina precoz de Extremadura ininteligible
Defunciones de nuestro ordenador contrarían nuestras labores cotidianas, suplementos indefinidos, disgregación de datos e infructuosas horas de quehacer implementado (Instalación del Sistema Operativo) o acoplamiento complementario (Programas del mismo), pudieran bien acortarse en extremo necesario.
La presente ha sido estructurada a complacencia del usuario anodino, simplificando tiempo y definiéndola en concepto de forma pormenorizada
Sin más dilación comencemos
(Proemio Fastuoso) Sistemas Operativos soportados
-Windows 2000(Pro, Server, Advanced)
-Windows XP (Pro, Home, N X64)
-Windows Server 2003 (Standard, Wed, Enterprise X64 R2)
Requisitos (Inexcusables)
nLite Version 1.3.5 o posteriorMicrosoft .NET Framework 2
Windows XP Pro
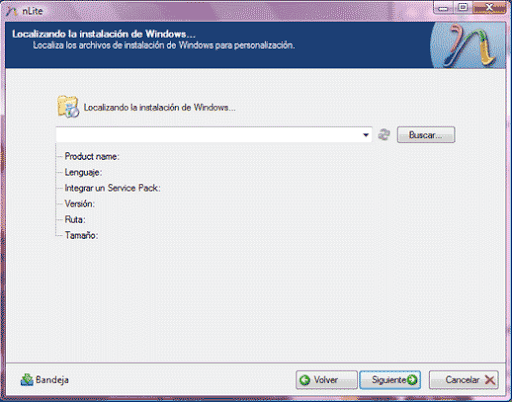
Localiza la instalación de Windows…. (DEBERA COPIARSE CON ANTELACION EN ALGUN DIRECTORIO O SUBDIRECTORIO DEL PC)
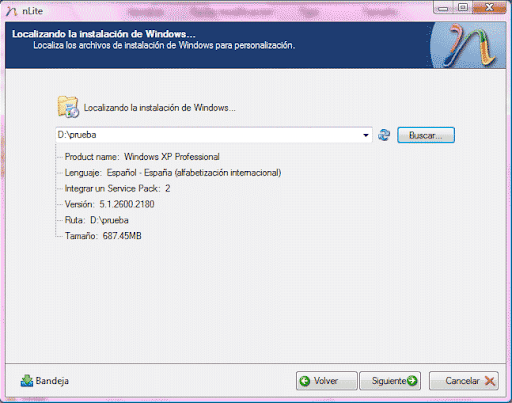
Una vez creada y direccionada la carpeta contenedora de la instalación de Windows se muestra, a modo de complemento descriptivo, todo lo relacionado con la misma.
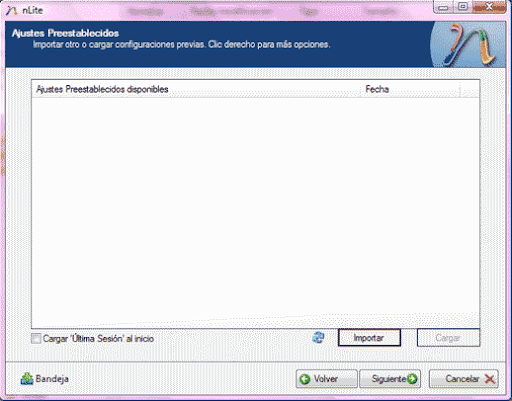
Ajustes preestablecidos, descompuesto estado en primera instancia, se utiliza para remontarse a configuraciones previas
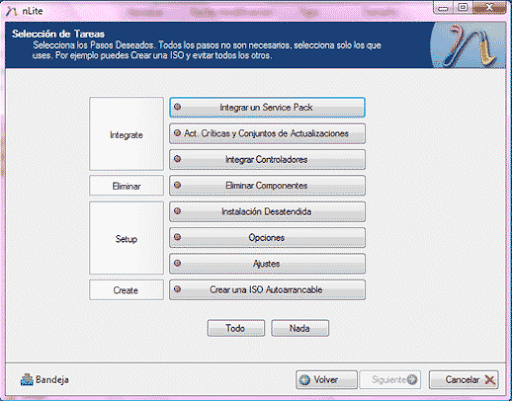
Estructura principal del supradicho complemento
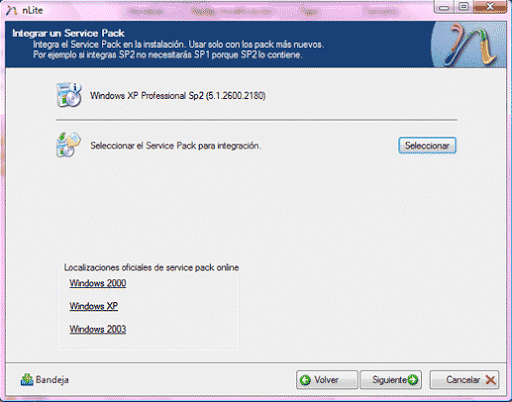
-Selecciona los pasos deseados (Todos los pasos no son necesarios en caso de configuraciones previas)-Integración de un Service Pack
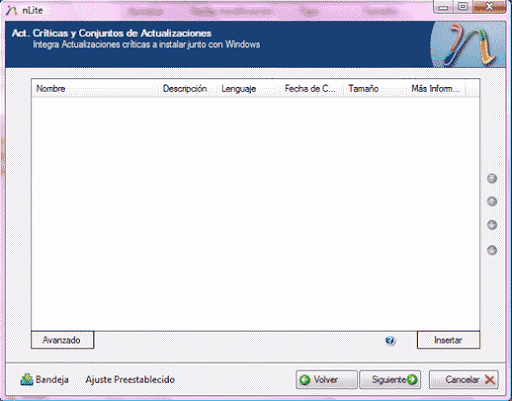
-Actualizaciones Críticas y Conjunto de Actualizaciones
-Integrar Controladores
-Eliminar Componentes
-Opciones
-Instalación Desatendida
-Ajustes
-Crear una imagen ISO auto arrancable
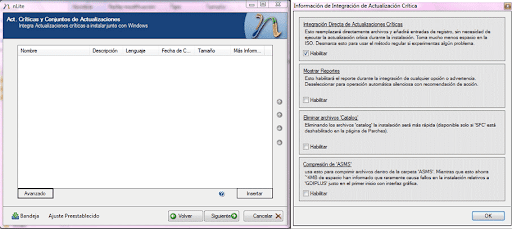
Mostrar reportes: Esto habilitará el reporte durante la integración de cualquier opción o advertencia.
DESELECIONAR PARA OPERACIÓN AUTOMATICA SILENCIOSA CON RECOMENDACIÓN DE ACCION
Eliminar archivos CATALOG: Eliminado los archivos catálogos la instalación será mas rápida (disponible solo si SFC está disponible en la pagina de parches)
Compresión de ASMS: Usa esto para comprimir archivos dentro de la carpeta ASMS. Mientras que esto ahorra 4 Mb de espacio han informado a raramente causa fallos en la instalación relativo a GDIPLUS justo en el primer inicio con interfaz grafica.
Programas implementables

Trabajo de mesa para confeccionar Bases de Datos
De seguro eres de los que piensan que dominan el arte de la creación de las bases de datos, de los que las hacen en “caliente” aunque le tome toda una madrugada llegar a terminarlas; pues bien te recomiendo que te leas este articulo de forma detenida ya que toca un tema que estoy seguro has olvidado por completo, a ese que llamamos trabajo de mesa, y que consiste en representar en el papel el sistema que vamos a hacer.
Esto del trabajo de mesa para la realización de bases de datos ha traído muchas controversias entre los especialistas que han trabajado aportando ideas sobre el tema, así que solamente mencionaré lo básico.
Primero debo decirles que todo parte del “análisis” que podamos lograr de una problemática que queramos resolver y que generalmente se puede resumir en cuatro principios básicos:
1. Se debe representar y comprender el ámbito de información del problema: Como ámbito de información se entiende tanto los datos, como los procesos o tareas del sistema analizado.
2. Se deben desarrollar los modelos que representen la información, función y el comportamiento del sistema: Deben mostrar qué hace el sistema y no cómo debe funcionar.
3. Se debe dividir el modelo (y el problema) de forma que se descubran los detalles de una manera progresiva (o jerárquica), de lo general a lo particular: Por esta razón es necesarios dividirlos en partes que se puedan entender fácilmente y establecer interfases entre estas partes, para poder realizar la función global.
4. El proceso de análisis debe ir de la información esencial (¿el que´?) hacia el detalle de la implementación (¿el cómo?).
Pues basándonos en estos principios lo primero que debemos realizar es un pequeño diagrama que represente cómo funciona “nuestro sistema” la cual llamaremos: diagrama de contexto o resumen del sistema. Para ello se deben conocer la notación básica para su confección que es la siguiente:
Notación para los diagramas
Denominación |
Definición |
Representación |
Notación |
Ejemplo |
|
Procesos |
Representan como las entradas se transforman en salidas. |
 |
Debe describir lo que realiza.VERBO + OBJETOEjemplo: |
 |
|
Flujos de Datos |
Representa la información que entra y sale de los procesos. |
 |
Debe corresponderse con su contenido. OBJETO + (ADJETIVOS)Ejemplo:No. carnet valido |
Flujos Divergentes |
Flujos Diferentes |
 |
 |
||||
Ficheros |
Representan la colección de los paquetes de datos en reposo. |
 |
Debe corresponderse con su contenido OBJETO (plural) + (ADJETIVOS)Ejemplo: |
 |
|
Este pudiera ser un diagrama de contexto para una situación dada y se basa en un caso hipotético clásico de la asignatura “Análisis y Diseño de Sistemas Informativos”:
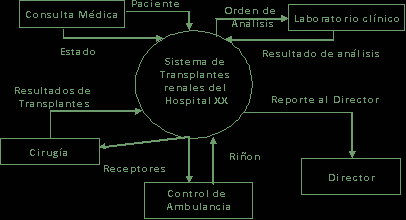
Obsérvese la sencillez y la limpieza con que se muestra todo el proceso en forma resumida.
Sin embargo en muchas ocasiones es necesario descomponer una función o tarea en otras más simples obteniéndose el Diagrama de la tarea correspondiente, el cual será un diagrama de nivel 1 (o de las Tareas Principales). A su vez una de las subtareas del nuevo diagrama pudiera descomponerse obteniéndose un nuevo diagrama (nivel 2), y así sucesivamente según el grado de detalle requerido se tendrán diagramas de niveles 3, 4, etc., siempre yéndose de lo mas general a lo particular. Por ejemplo tengamos:

El Diagrama 3 permite mayor nivel de detalle de la tarea 3 del Diagrama de Nivel 1. El Diagrama 3 obtenido es un diagrama de nivel 2 estando balanceado con relación a su proceso padre, es decir, salen y entran los mismos flujos de dados que entran y salen de la tarea 3 en el Diagrama de Nivel 1 F1 y F2 entran y F3 sale). Por otra parte se realiza las mismas acciones sobre la Base de Datos (leer y escribir), lo que en el nuevo Diagrama se detalla las tablas que se utilizan de la Base de Datos por cada proceso.
Pudiera tenerse tantos diagramas de nivel 2 como numero de Procesos que tengan el Diagrama de nivel 1, así en el ejemplo anterior pudiera tenerse el diagramas 1 y el diagrama 2 correspondientes a las tareas 1 y 2 en caso de necesitarse detallar estas, ambos serán de nivel 2.
Supongamos que sea necesario descomponer la tarea 3.2 del Diagrama 3 obteniéndose el Diagrama 3.2 este de nivel 3.

Note que este esta´ balanceado con su proceso padre, es decir entra el flujo F2, se escribe en las tablas 1 y 4 y se lee de la tabla 3. En este caso la tarea padre 3.2 del Diagrama 3 se dividió en las tareas 3.2.1 y 3.2.2.
Notemos que en todo Diagrama los Procesos (tareas) están enlazados formando el sistema que compone al proceso. Las lijaduras de estas uniones son los depósitos de datos en los cuales las tareas hacen las acciones de leer, escribir o ambas.
Todo diagrama sin importar el nivel deben cumplir con:
1. Utilizar nombres apropiados.
Procesos: Verbo + Objeto
Flujos de Datos: Objeto + Adjetivos
Almacenes de Datos: Objeto (plural) + Adjetivo
2. Las acciones sobre las tablas son:
Actualización: lectura y escritura.
Búsqueda: lectura.
Guardar: escribir
3. Todo proceso o tarea debe estar numerado: Ser consecuente al numerar los procesos (tareas) hijos en relación con la enumeración del padre.
4. Evitar Diagramas muy complejos: Un Diagrama de flujo de datos debe tener entre 5 y 9 procesos (tareas), debiendo ser de complejidad similar.
5. Evitar procesos sumideros y fuentes: En los procesos sumideros solo entran Flujos de Datos, mientras que los fuentes solo salen Flujos de Datos.
6. Evitar depósitos de datos sumideros y fuentes
7. Garantizar que los Diagramas estén balanceados respecto a la tarea padre que le dio origen. En el caso del Diagrama 1 debe estar balanceado con respecto al Diagrama de contexto y este ultimo con relación a la Tabla de Eventos.
8. Los procesos (tareas) de un Diagrama de Flujos de Datos deben estar lijados entre si formando un sistema.
Para el próximo artículo hablaremos sobre como tabular los procesos y flujos del sistema (Tabla de Eventos).