
En el inmenso mundo del 3D sobran formas de hacer algo como esto. A través de unos cuantos pasos aprenderemos a cómo modelar el logo de esta revista semanal (el Sombrero Negro) en 3d Studio Max 8.0, usando splines y edición de malla, levantado desde un plano superior. Esta forma de modelado es muy usada en infografías arquitectónicas más complejas, aunque en este caso nuestro plano superior no será más que dos círculos concéntricos. Espero que sirva más que de guía práctica de ejercicio para aquellos que se inician en el mundo de las X, Y y Z.

BlackHat en 3D
Antes que nada se aconseja el uso de métodos abreviados del teclado para reducir el tiempo de creación, así como trabajar con la pantalla dividida en las 4 vistas fundamentales: Perspective, Left, Top, Front). Luego comenzamos a trabajar:
1- Primero vamos al menú Create»Shapes»Circle, y creamos un círculo de radio 80. En el panel de Propiedades ponemos interpolación en 12; esto es para que al resultado final no se le vean los polígonos y cree un mejor suavizado.
2- Ahora usamos la herramienta Escalar, aunque primero nos aseguramos de que esté en modo "Escala uniforme". Seleccionamos el círculo y escalamos hacia adentro presionando Shift, sólo por los ejes X y Y. Es importante que el eje Z quede fuera de nuestra selección. Se formará un nuevo círculo y al soltar el clic nos mostrará el cuadro de opciones de clonación. Ahí pondremos el nombre al nuevo círculo y seleccionaremos Copy de las tres opciones que nos son mostradas.

3- Damos Aceptar y luego clic derecho, convertir a Editable Spline. En las propiedades de Editable Spline, clic en Attach y seleccionamos el otro círculo para que formen un solo objeto.
4- Nuevamente clic derecho. Ahora que vamos a convertir a Editable Poly, como resultado veremos cómo se rellena el espacio entre ambos círculos con malla.
5- Seleccionamos border (tecla 3) del nivel de subobjeto de la malla poly (panel Selection), ubicamos y marcamos el borde del centro (el antiguo círculo pequeño) y lo subimos un poquito por el eje Z, sólo para darle el toque semi-inclinado de las alas del sombrero.
6- En Selection»Polygon, seleccionamos toda la malla y Extruimos (con Alt + E) un poco... sólo un poco hacia arriba (eje Z)
7- Nuevamente seleccionamos border, tomamos el borde del centro (el antiguo círculo pequeño, otra vez) lo movemos por la Z hacia arriba; no mucho, sólo lo suficiente para hacer el aro de cinta negro que le da la vuelta al sombrero.

8- Volvemos a seleccionar el borde y escalamos uniformemente (ahora sí escalamos todos los ejes) hacia adentro un poco el borde, luego volvemos a tomar la herramienta de Mover y seguimos estirando el borde hacia arriba con el Shift presionado, Luego volvemos a la herramienta Escalar (de modo uniforme) y estrechamos un poco la parte alta del sombrero.
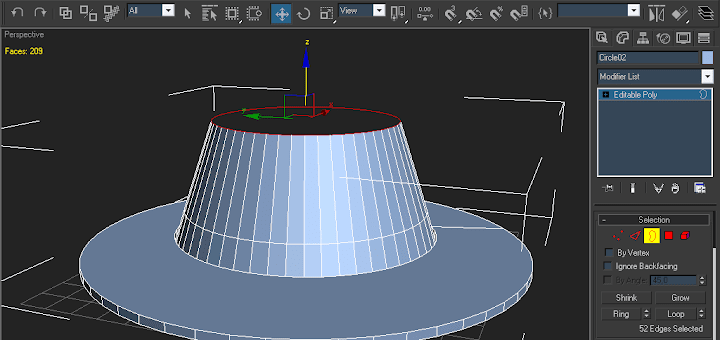
9- Seguimos trabajando en el mismo borde con la herramienta Escalar (siempre en modo uniforme) y esta vez volvemos a escalar (sólo por X y Y) hacia adentro presionando Shift de modo que se cierre lo suficiente el agujero. No importa dejar un pequeño hoyito, eso se solucionará en el el siguiente paso.
10- Ahora seleccionamos Vertex (tecla 1) y en la vista superior (T) seleccionamos los vértices que conforman el agujero pequeño de la parte superior. Luego vamos a Collapse en las propiedades de la malla Editable Poly. Volvemos a Perspectiva... ya está casi listo nuestro BlackHat.
11- Ahora vamos al suavizado, (usar vista lateral, tecla L) seleccionamos los polígonos que componen la parte superior del "hat" y, en Polygon Properties»Smoothing Groups, seleccionamos el 1 (éste es el grupo uno de suavizado).

Luego hacemos lo mismo para la cinta del sombrero poniéndolo en 2 pero además en Set ID le asignamos 2 también; lo mismo para las parte de abajo del sombrero, pero sin asignar ningún ID y poniéndolo en 3 o en 1 para que tome el mismo suavizado de la parte superior.
12- Solo faltaría texturizar, pero basta con ponerle un color gris a todo el modelo. Luego seleccionamos los polígonos que corresponden a la cinta. Para esto vamos a Select ID y ponemos 2, así recuperamos la selección hecha previamente, Luego presionamos M y le asignamos cualquiera de los materiales (esferas grises) que aparecen en el editor de materiales. Posteriormente seleccionamos el material y en Shader Basic Parameters ponemos Anisotropics en el menú desplegable. Ponemos en difusa el color Negro (en Anisotropic Basic Parameters), asignamos: Specular Level a 149, Glossiness a 25, Anisotropy a 50 y Orientation 0.
13- ¡Terminado! A los que no le guste mucho el acabado del sombrero de la parte de abajo pueden ponerle un modificador Shell, y dos o tres luces Omni, F9 (para el render) ¡y ya está! También pueden jugar con los valores de anisotropía y probar con texturas y otros materiales así como distintos tipos de luces. El resultado final, según los pasos de este texto, debe quedar más o menos igual a la primera imagen. Todo en dependencia del ángulo de la cámara y las luces.




